غزال زیاری- چند روز پیش بود که استارت آپ فرانسوی Mistral از اپلیکیشن Le Chat برای سیستمهای عامل iOS و اندروید رونمایی کرد. این برنامه بهعنوان یک چت ربات یا دستیار هوش مصنوعی معرفیشده و در این مسیر با غولهایی ازجمله ChatGPT، Claude و Gemini رقابت میکند.
برنامه Le Chat اکثر قابلیتهایش را بهصورت رایگان ارائه میدهد و البته با محدودیتهای ارتقا یافته در سطحی حرفهای با پرداخت هزینه ماهانه 14.99 دلار در اختیار کاربران است. Le Chat قابلیتهای جستجوی وب، تصویر و درک سند را در کنار تفسیر کد و تولید تصویر ارائه میدهد.
ازآنجاکه برنامههای کاربردی دستیار هوش مصنوعی این روزها در بازار بهوفور یافت میشوند، شرکت جدیدی که قصد ورود به بازار را داشته باشد باید بتواند نکات متمایز قابلتوجهی را ارائه دهد. دراینبین، میسترال مدعی است که مدلهای کم تأخیر آن توسط سریعترین موتورهای استنتاج کره زمین در اختیار کاربران هستند و درعینحال ادعا میکند که سریعتر از هر دستیار چت دیگری قادر است تا با بهرهگیری از ویژگی Flash Answers، در هر ثانیه تا 1100 کلمه پاسخگوی کاربران باشد.
سبقت از رقبا به لطف Cerebras
حالا این سؤال مطرح میشود که رمز و راز این سرعت جادویی Le Chat در چیست؟ پاسخ ساده است؛ بهرهگیری از Cerebras Inference، سرویسی که امکان پردازش با سرعتی بالا را به برنامههای هوش مصنوعی ارائه میکند.
طبق گفته مسئولان این شرکت، Cerebras Inference سریعترین ارائهدهنده استنتاج هوش مصنوعی در جهان است و بدین ترتیب Le Chat را 10 برابر سریعتر از GPT-4o، Claude Sonnet 3.5 و DeepSeek R1 کرده است. مقامات این شرکت درعینحال یادآوری کردند که مدل Mistral Large با 123 میلیارد پارامتر پشت Le Chat قرار دارد.
کارشناسان برای تولید بازی Snake و با استفاده از پایتون، به مقایسه Mistral و Cerebras Le Chat با Claude 3.5 Sonnet و ChatGPT-4o پرداختند.
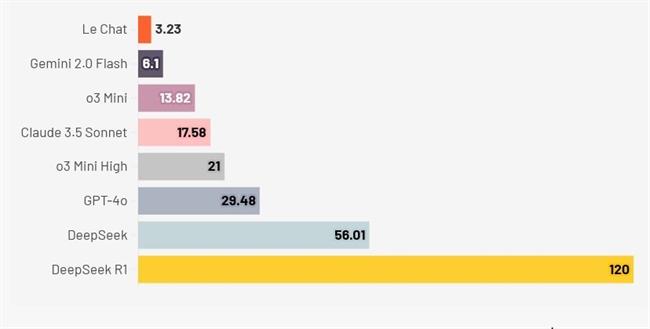
نتایج به نمایش درآمده در ویدیوی YouTube Mistral نشان داد که ChatGPT با 85 توکن در ثانیه، کلود 120با توکن در ثانیه،عملکرد به مراتب ضعیفتری نسبت به Le Chat با 1100 توکن در ثانیه داشتند.
در ویدیوی منتشرشده توسط Cerebras، برای Le Chat، تنها 1.3 ثانیه زمان نیاز بود تا کار را انجام دهد؛ Claude 3.5 Sonnet برای انجام همان کار 19 ثانیه زمان نیاز داشت و همین کار برای Chat GPT-4o حدود 46 ثانیه زمان برد.
Cerebras در یک پست وبلاگی دراینباره توضیح داد: «این عملکرد توسط معماری استنتاج مبتنی بر SRAM در Wafer Scale Engine 3 در ترکیب با تکنیکهای رمزگشایی گمانهزنی که با همکاری محققان Mistral ایجادشدهاند، ممکن میشود. »
دراینبین، چندین کاربر نیز در رابطه با این ادعاها اظهارنظر کردند. کاربری به نام Marc on X توضیح داده که این مدل "به طرز شگفتانگیزی سریع" است و اشاره کرد که با استفاده از این برنامه جدید، موفق شده تا یک برنامه ساده React را در کمتر از 5 ثانیه بسازد.
کاربر دیگری به نام Pol Maire نوشت: «Le Chat محصول MistralAI، ده برابر سریعتر از ChatGPT است. شاید حتی 100 برابر.»
آنچه در آزمایشهای دنیای واقعی مشاهده شد
در AIM آزمایشی درباره برخی از مدلهای پیشرو انجام شد که تا حدودی متفاوت بود. در این آزمایش از مدلهای هوش مصنوعی انتظار میرفت تا یک مسئله شیمی که یکی از سؤالات IIT-JEE که یکی از دشوارترین امتحانات جهان در نظر گرفته میشود را حل کنند.
هوشهای مصنوعی GPT-4o، o3 Mini، o3 Mini High، Anthropic's Claude 3.5 Sonnet، DeepSeek R1، Gemini 2.0 Flash گوگل و البته Mistral's Le Chat برای این آزمایش انتخاب شدند.
سؤال طرحشده بدین ترتیب بود: «برای تبخیر یخی در دمای 10- درجه سانتیگراد و رساندنش به دمای 110 درجه سانتیگراد به چه میزان گرما نیاز خواهد بود؟ لازم به ذکر است که جرم یخ 10-3 کیلوگرم است.»
Le Chat سریعترین مدلی بود که توانست به پاسخ برسد، اما با یک هشدار همراه بود.
زمان موردنیاز مدلهای هوش مصنوعی برای حل مسئله شیمی
درحالیکه Le Chat Mistral بهعنوان سریعترین مدل ظاهر شد، اما همیشه از پاسخهای Flash استفاده نمیکرد که احتمالاً دلیلش آن بود که در این آزمایش از نسخه رایگان استفاده شده بود. Le Chat در سه بار از شش باری که مدل مورد آزمایش قرار گرفت، خروجی را در کمتر از 4 ثانیه برگرداند؛ اما فلش Gemini 2.0 گوگل در تمام دفعات آزمایش، خروجی را زیر 6 ثانیه برگرداند.
بدین ترتیب این سؤال مطرح میشود که آیا Flash Answers باوجودی که بهصورت پیشفرض فعال میشود، میتواند هر بار وارد عمل شود یا خیر؟ این را باید در نظر داشت که در این آزمایشها از نسخه رایگان دستیار Le Chat استفاده شد و نسخه حرفهای، محدودیت ارتقا یافتهای را برای ویژگی Flash Answers فراهم میکند.
بهعلاوه، سرعت عملکرد این مدلها به ماهیت پرسوجوها نیز بستگی دارد. مدلهای استدلالی، با زنجیره طولانی افکار خود، دقت در پاسخ را در اولویت قرار میدهند و در نتیجه به زمان بیشتر نیاز خواهند داشت.
مثلاً زمانی که prompt را با DeepSeek R1 آزمایش کردیم، تکمیل مشکل با زنجیرهای از افکار که شامل مراحل تأیید بود، بیش از یک دقیقه طول کشید. در آن مرحله مدل گفت: «اجازه دهید بررسی کنم که آیا همه مقادیر درست هستند یا خیر. آیا از گرمای ویژه مناسب برای بخار استفاده کردهام یا خیر و غیره.»
علاوه براین، زمان زیادی طول کشید تا اطمینان حاصل شود که پاسخ با تعداد مناسب ارقام اعشاری ارائهشده است.

آزمایشی از Artificial Analysis نشان داد که OpenAI o3-mini سریعترین مدل در بین رقباست که 214 توکن در ثانیه تولید میکند که آماری بالاتر از 17 توکن در ثانیه o1-mini است.
بر اساس تجزیهوتحلیل Artificial Analysis، o3-mini همچنین در شاخص کیفیت خود به امتیاز بالای 89 دستیافت که بدین ترتیب قابلرقابت با o1 (90 امتیاز) و DeepSeek R1 (89 امتیاز) به نظر میرسد. این شاخص کیفیت، قابلیتهای کلی مدل هوش مصنوعی را بهصورت کمّی بررسی میکند.
OpenAI مقیاس زمان استنتاج را برای ارائه خروجیها با سرعت بالاتر اولویتبندی کرده است. با قابلیتهای استنتاج Cerbreas، به نظر میرسد Mistral به این مسابقه پیوسته است. علاوه بر این، نبرد مداومی در رابطه با سرعت توکن بین ارائهدهندگان استنتاج مثل Cerebras، Groq و SambaNova وجود دارد.
این جاهطلبیها برای ارائه پاسخهایی با سرعتبالا با آنچه جنسن هوانگ، مدیرعامل انویدیا در سال گذشته گفت، مطابقت دارد. او آیندهای را متصور بود که در آن سیستمهای هوش مصنوعی وظایف مختلفی مثل جستجوی درخت، زنجیرهای از افکار و شبیهسازیهای ذهنی را انجام میدهند، پاسخهای خود را بازتاب میدهند و در زمان واقعی و در حدود یک ثانیه پاسخگو هستند.
منبع: analyticsindiamag
227227
