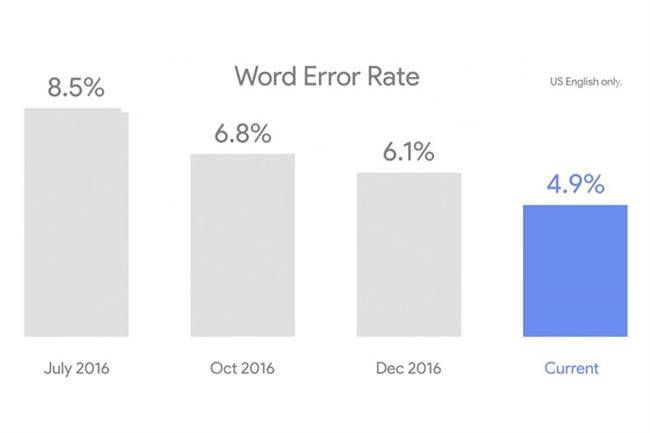
ساندار پیچای، مدیرعامل گوگل، در رویداد I/O امسال روی سن ظاهر شد و اعلام کرد که ضریب خطا در تکنولوژی تشخیص گفتار این کمپانی به 4.9 درصد کاهش یافته است. بهعبارتی گوگل در هر 20 کلمه، یک کلمه را به درستی تشخیص نمیدهد. این رقم به مراتب بهتر از آماری است که در سال 2013 اعلام شد. در سال 2013 ضریب خطای گوگل 23 درصد بود.
یکی از موضوعاتی که گوگل در کنفرانس روز گذشته بسیار روی آن تاکید داشت، هوش مصنوعی بود. یادگیری عمیق، گونهای از هوش مصنوعی است و برای تشخیص دقیقتر تصاویر و گفتار میتوان از آن بهره برد. در این روش اطلاعات زیادی به سیستم آموزشی به نام شبکه عصبی داده میشود و با تحلیل آنها کامپیوتر میتواند حدس بزند. پیچای در کنفرانس گفت:
ما بهوسیله فرامین صوتی از محصولات مختلفی استفاده میکنیم. به همین علت است که کامپیوترها در درک گفتار پیشرفت میکنند. ما دستاوردهای شگرفی در این زمینه داشتهایم؛ اما از سال گذشته با پیشرفتهای محسوسی مواجه شدهایم. میزان خطای ما حتی در محیطهای شلوغ و پر سر و صدا در حال کاهش است. به همین علت است که اگر با گوگل از طریق تلفن هوشمند یا گوگل هوم صحبت کنید ما میتوانیم با دقت بسیار بالایی صدای شما را تشخیص دهیم.
برای مقایسهای کوتاه، جالب است بدانید که مایکروسافت نیز در این زمینه فعالیت میکند و طبق آنچه در اکتبر سال 2016 اعلام کرده است، ضریب خطایش به 5.9 درصد رسیده است. البته باید گفت که مشخص نیست آیا هر دو کمپانی از یک استاندارد استفاده میکنند یا خیر.
کمپانی گوگل از سال 2012 تاکنون توانسته ضریب خطا در تشخیص گفتار را از 30 درصد به 4.9 درصد برساند که موفقیت بزرگی محسوب میشود. مسئولان این کمپانی، استفاده از شبکههای عصبی را دلیل پیشرفتشان دانستهاند.
